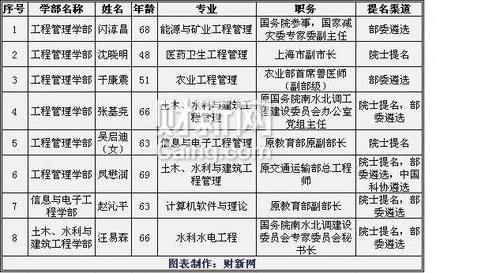
高文功放 中国工程院院士高文:人工智能再放大招 计算机视觉助力打造智慧城市
[ 亿欧导读 ] 作为智慧城市的大脑,应该包括先进的数字视网膜功能,这个功能应该是一个复眼,但不是像现在很多单一眼组合起来的复眼,而应该是一个功能集成、能集编码和特征表达为一体并进行联合优化的一套视频和图象感知系统。

以下内容根据速记演讲整理(有部分删减):
下面有请中国工程院院士,国家自然科学基金委员会副主任,中国计算机学会理事长,北京大学教授,博士生导师高文先生演讲,有请!

高文:各位专家、各位领导早上好!
刚才的报告非常有趣,现在人工智能应该说是我们这个领域最大的热点,人工智能里有若干分支,脑机接口肯定是其中一个分支,计算机视觉是另外一个分支。我今天跟大家分享计算机视觉问题,包括城市大脑与数字视网膜。

智慧城市
我们在智慧城市中不可避免应有一个决策支持系统,我们把它叫城市大脑。如果把智慧城市里所有的传感器,不管是图像的、视频的还是其他各种各样的数据全都汇总到城市大脑系统中去,然后再由城市大脑计算得出一个结果,最后得到一个响应。

就像刚才脑机接口一样,城市也需要有类似的响应。怎么样能响应得更好?这显然是一个我们必须要研究的问题,其中包括很多人工智能的问题。在这个城市大脑里我们怎么能够让大脑响应得准确、快速,也是我们必须要考虑的问题。所以我们首先要考虑的就是关于智慧城市的问题。

智慧城市实际上不是一个新名词,最开始由IBM提出这个概念以后很多地方都在跟踪,都在做。到目前为止,中国有几十个智慧城市的试点单位,它们已经做的不错了。其中,我个人认为做得比较好的是杭州的智慧城市,它系统地解决了一个问题。什么问题呢?城市交通的问题。我们看看它怎么解决的。

到目前为止,杭州大概有两百万辆车,其中九千辆公交车,覆盖一共六百条线路,涉及的交叉路口非常多,大概有五万条道路,八万个交叉路口。这样一个非常复杂的系统,是否可以对杭州的信号系统进行控制,对城市交通信息进行升级改造?当然可以。

我们看看杭州怎么做的。杭州把信号灯路口的视频搜集起来,交给城市大脑进行分析,在分析几个月数据后,把所有情况分成三类情况:第一类情况是道路低饱和度,第二类是道路中饱和度,第三类是道路高饱和或者叫准饱和。

经过大数据的分析,发现在整个杭州道路上低饱和状态下城市车辆的行驶速度大概是每小时37公里平均,中饱和大概是30公里,在准饱和或者接近饱和大概是22公里,这是整个城市的交通状况。

用城市大脑优化模型计算以后,重新驱动信号灯系统。结果是什么呢?根据系统开发商阿里云给出的报告显示,结果是在低饱和情况下大概平均速度可以到43公里,中饱和度在35公里,准饱和度在26公里。也就是说什么基础设施都不需要改变,只是把数据经过这个城市大脑重新计算一下,可以对道路通畅率在低饱和情况下提高16%、中饱和情况下提高17%,准饱和情况下提高18%,平均提高17%。

这就是城市大脑给城市运行带来的好处。
这是怎么做到的?这里显示的就是那套城市大脑系统:上面有操作和服务平台,中间是算法平台,再往下数据交换和集成平台,用于各类传感信号的搜集和集成。这里既有摄像头的信号,也有路下面埋的线圈的信号,各种各样信号搜集起来都送到城市大脑里进行计算。
然而,现有摄像头的种类很多,并且各个摄像头都仅负责某一方面的功能,例如监视摄像头采集的视频专门用于人工监视与数据保存;人脸抓拍摄像头专门做人脸识别,比如看看这个路上有没有人在走;电子警察专门做车牌识别,比如车跑过去马上就能识别出来这个车的牌照号码是多少;还有一些卡口摄像头,在每一个高速公路入口出口都会有。
可以看到,每一个摄像头都只执行单一功能,要么编码存储要么识别,而所有这些东西都会送到云端的系统。当然它也可能是分级的,可以通过第二梯队分中心,再送到云端。
但是这个系统有两个问题。采集的海量图像视频,后边云端计算机直接识别它是很困难的,现有模式大多需要由人来看。所以我们可以看到,经常发生了一起案件,会有几十个甚至上百警察看这个视频,最长看上百小时才能把要找的人或者车或者事件查出来。显然,视频感知系统实际上是不聪明的。不聪明的原因是什么?经过仔细分析,技术上实际上有两类问题,第一类多媒体大数据处理瓶颈,第二类是人工处理系统的瓶颈。
多媒体大数据
多媒体大数据有三个比较难解决的技术问题。一是存储比较难。像现在的这种智慧城市里的监控系统,它存数据可能短的是存一个星期,长的是存三个月。为什么不能永久存下去呢?因为这里数据量太大,存起来的成本会非常高,所以比较难存储,这是它首先要解决的一个巨大挑战。
第二个是比较难识别。尽管早期摄像头正在慢慢被淘汰,但是还有相当数量早期的摄像头,这些摄像头的分辨率比较低,光学参数设置略低级一点,所以它们采集的视频用眼睛看还马马虎虎,但是计算机识别完全不可能。此外,不同摄像头拍的东西怎么确认是同一个物体,如同一辆车?这个一般就要看车牌。
那如果无牌或者套牌怎么办?同样,同一个人同一天穿着同样的服装、戴着同样的饰品,在一个摄像头下走过去,你很容易确认他是同样的人。但是他换了衣服你是否还能确定是同一个人?我们称这个是对象再标识问题,这是多媒体大数据中非常具有挑战性的问题。
应对这样的挑战问题,技术上有各种各样可能的策略。为应对存储难,可以试图找到更高性能的编码压缩算法,这是一条出路。对于难检索问题,可以想法找到更好的特征,使得这个特征能够有效,这样就可以提高识别性能。对于跨摄像头的对象再识别问题,那就需要我们对行为的分析更上一个层面才有可能解决。
第三是摄像机网络的问题。除了刚才多媒体大数据的一个问题以外,其实还有一个很困难的问题,就是我们现有摄像机网络固有的问题。现在用的摄像机都是单一功能的摄像头,这个实际上跟人比较起来差很多。我们人有一双眼睛,而且这一双眼睛,左眼右眼合起来看与分工看,是有不同的。
实际上一般的视觉处理靠一只眼睛就可以了,但是这一只眼睛的功能是很神奇的:它既能看到很细的细节,也能欣赏一个画面,欣赏一个人长的漂不漂亮,欣赏他脸上的很多细节,同时它也能非常宏观的看这个场景里有几个人,男的女的老的少的或者是怎么样。
但是现在城市大脑视觉系统不是一样的,有各种各样的眼睛(即摄像头),有专门看车牌的眼睛,有看人的眼睛,有做压缩存储的眼睛,这么多眼睛合在一起其实做起来就非常困难。所以我们现在认为,系统不进化不演进是不行了,我们必须向人学习,做人工的视觉系统,这样使得现在单一功能的摄像头尽快把它淘汰掉,换成多功能的,我们叫一对多模式的摄像头,一个摄像头它可以做编码,也可以做识别等等。
单一功能摄像头
单一功能摄像头有很多问题,时间关系没办法进一步展开。简单地说存在三个主要的问题。一个是延时比较长,第二个准确率比较低,第三个利用率比较低。
为什么说延时比较长呢?因为我们使用的是单一摄像头,在城市大脑或者智慧城市里通常由这个摄像头拍了视频,把它编码压缩以后,通过一个编码器把它编码压缩,通过网络传递到云端,云端再把它解开,在解码后图像序列上抽取特征,最后再识别它是什么,这个流程下来大概需要1.5秒到5秒这样的一个延时。所以这个流程使得在我们监控系统中,不仅是实时性不行,识别的准确率也不高。
为什么识别的准确率不高呢?因为在编码的时候为了使得带宽变小,它设定的编码参数比较极端,把很多可能十分有用的特征都给你压缩掉了或过滤掉了,在这样的图像视频上去做识别的时候,识别率会非常低。我们曾经做过很多这样的实验,在不同人脸识别、不同车辆识别的条件下,我们测量的结果(编码参数设定在QP值等于38)还是可以的;如果大于这个值,编码码流的质量人眼看还是可以,但是你要是用它做模式识别,性能就会下降一半以上。
刚才说QP值等于38是意味着什么呢?我们在家里面看着电视高清频道,大家看着比较好的,编码QP值大概是32;编码QP值到了38实际上失真很厉害,眼睛已经能看出画质损伤了;到45、51、63这样几个呢?50左右是目前监控系统用的编码参数,实际上压缩码流已经把很多东西丢掉了,所以你用它做识别是很难很难一件事。
第三个问题是利用率比较低。城市大脑对应的监控系统,大部分视频编码存储起来后就扔在那儿不用了,慢慢就有新的视频把它覆盖掉了。其实作为大数据,图像视频中可以分析得到很多有用东西,当然要想在其中进行分析,编码的时候就要把很多特征提取出来,后续才能在特征基础上进行数据分析和学习。所以这个也是目前系统里面临的一个问题。图像视频数据大,但并没有真正变成大数据。
城市之眼
作为一个城市大脑,它的城市之眼应该要克服刚才说的四个问题,包括存储难,检索难,识别难和功能多样化。要想解决这四个问题,显然现有的系统是做不到的。那该怎么办?
我们要演进,要实现智慧城市的城市大脑,整个传感系统就必须进化。怎么进化呢?现在城市的眼睛更像复眼,它是神经末梢,我们要把它单一功能的摄像头升级演进成多功能的摄像头。摄像头在编码的同时要能把所有的特征同时编码提取出来,传到云端进行识别,这样后台城市大脑的决策才有可能是准确的。技术上我们已经有完整的技术架构支持。
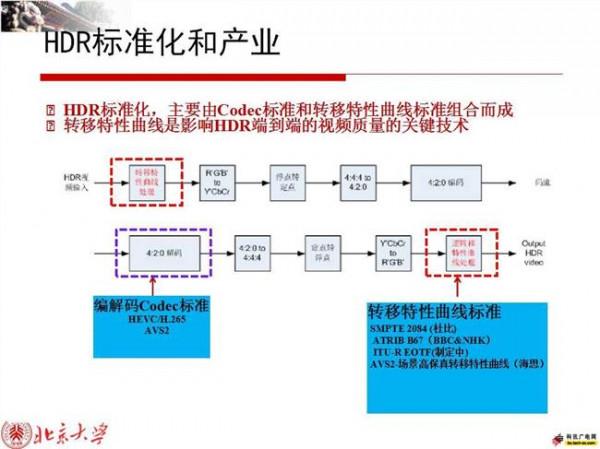
一个是我们可以提高编码压缩的效率,我们国家很大的团队已经做了十几年,不停做视频编码这方面的工作,我是这个团队的代表人。我们现在这个团队已经做出了中国自己的国家标准和国际标准,这个标准比国内现有的编码效率提高40%。针对识别难,我们提出了一套特征编码的技术体系,我们也把它做成标准,制订了一套全新的国际标准。
数字视网膜
第三个问题,原来都是单一摄像头,编码需要优化的,你给定我一个码率,我要计算经过一个优化函数能得到的最小损失是什么。以前优化都是针对单一摄像头,进行单目标优化。未来我们的一个摄像头具有多个功能,因此需要对它进行联合优化,理论上我们把它叫R-D和R-A优化联合优化。
具体来说,R-D是为了做高效编码用的,R-A做高效识别用的。传统RDO是面向编码压缩的优化,但现在我们需要面向识别准确率也进行优化,因此需要进行联合优化。联合优化可以做很多实验,结果表明比单一优化效果更好。具体通过这样一个优化目标函数来做,通过对这些参数的优化我们可以得到一个联合优化的结果,使得整个优化目标最好。
有了前面几个技术,把它们集成到一起,最后要把它做成数字视网膜。这样一套系统一旦推出来以后,一个摄像头可以既管视频编码又管特征表达,这样既能做存储用同时也能做识别用,从而能够对城市大脑的前端视觉或者是视网膜提供最完整的支持,这套思路现在已经开始在一些地方进行研发和布局。
欢迎大家一起来参与这样一个新的或者是演进中的或者是革命性的变革中,这里会有很多机会。当然想做这个东西有很多标准要遵从。这些都是我们团队花很长时间汇集包括国内一些研发力量和国外一些专家智慧一起做出来的标准,并且已经是正式批准了的标准,其中有很多都是开源的东西,大家可以获得标准的开源代码,然后做自己产品研发。
由于时间关系我直接跳入最后的结论。作为智慧城市的大脑,应该包括先进的数字视网膜功能,这个功能应该是一个复眼,但不是像现在很多单一眼组合起来的复眼,而应该是一个功能集成、能集编码和特征表达为一体并进行联合优化的一套视频和图象感知系统。此外,这个系统需要有相关标准支持,欢迎大家多做一些这方面实现推动工作。







![>高文院士 高文[中国工程院院士、北京大学教授]](https://pic.bilezu.com/upload/d/10/d101d9e07c20ec98b5c7ae1efbee14c3_thumb.jpg)







{kind=link}